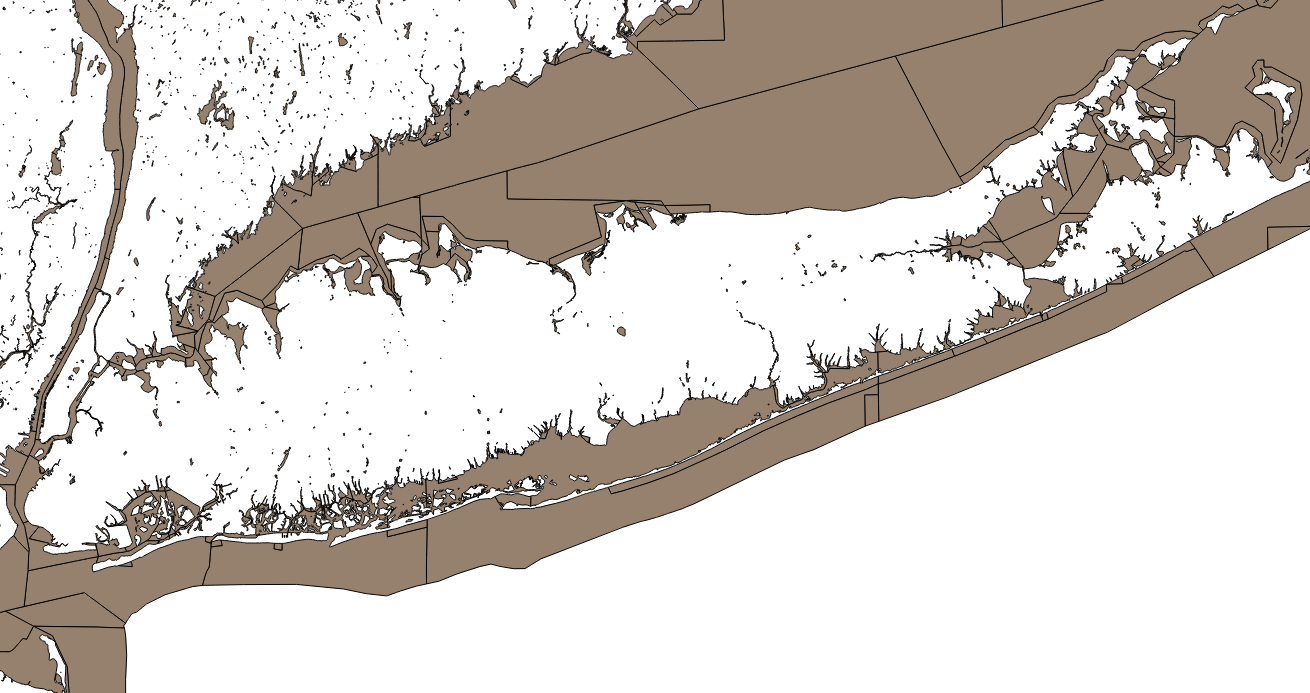
I have a PostGIS polygon layer with a lot of small “islands” (actually, lakes and ponds), polygons which are not touching any other polygons. I wanted to delete them from the layer, or rather, since I wanted to keep a version with and without the islands, I wanted to copy only the polygons with neighbors to a new table. I’ll show the solution first, and then how I got there.
SELECT * FROM table WHERE gid IN ( SELECT DISTINCT unnest(array[a.gid, b.gid]) AS gid FROM table a JOIN table b ON (ST_Intersects(a.geom, b.geom) AND a.gid < b.gid) )
The approach is to determine the gid (unique ID field) of the polygons that satisfy the requirements, and then grab the complete records associated with them. It’s a little bit odd, so let me show you what I started with.
Since we want to compare the polygons in this layer to the other polygons in the same layer, we’re doing a self-join, using a and b as the table aliases. I used a standard SQL trick for finding records in one table without matching records in a joined table, a LEFT JOIN b ON (...) WHERE b.any_field IS NULL. The LEFT JOIN returns all records from table a (the “left” table) whether or not there are matching records in table b, and the IS NULL criteria selects specifically those records that are unmatched. So my first attempt to select islands was:
SELECT a.*
FROM table a LEFT JOIN table b
ON (ST_Touches(a.geom, b.geom))
WHERE b.gid IS NULL
Unfortunately the LEFT JOIN prevents the query planner from being able to use the spatial index on the geom column. The query took ~50s to run on a small (23,000 record) test table, but I wanted to run it on a 2 million record table. In order to make use the spatial index, I switched to an inner join and came up with:
SELECT DISTINCT ON (a.gid) a.*
FROM table a JOIN table b
ON (ST_Intersects(a.geom, b.geom) AND a.gid != b.gid)
Now we’ve switched to finding polygons with neighbors, rather than islands (polygons without neighbors). The join condition matches up all polygons that touch each other using ST_Intersects() (polygons that touch also intersect), as long as they do not have the same gid, i.e, are not the same polygon (since unlike ST_Touches(), a polygon *does* intersect itself). But a polygon might have several neighbors, and that polygon would appear multiple times in the resultset (once for each neighbor). The DISTINCT keyword makes sure that each polygon appears only once in the resultset.
This version performed better on the small table, taking only 15s, but took 1 to 2 hours (on two different computers) on the larger table. At this point I asked for help on the PostGIS-users mailing list. Rémi Cura suggested the following:
WITH direct_comp AS (
SELECT a.gid AS agid, a.geom AS ageom, b.gid AS bgid, b.geom AS bgeom
FROM table AS a JOIN table AS b
ON (ST_Intersects(a.geom, b.geom) AND a.gid < b.gid)
)
SELECT agid AS gid, ageom AS geom
FROM direct_comp
UNION
SELECT bgid AS gid, bgeom AS geom
FROM direct_comp
What this is doing is using a Common Table Expression with a somewhat unusual join. Previously I used a.gid != b.gid to prevent any polygon from matching itself, but this means that every polygon is compared to every other polygon twice, because each polygon appears on both sides of the self-join (i.e. in table a and table b). Rémi cleverly cuts the number of comparisons in half by using a.gid < b.gid. Imagine comparing polygon 1 on the left to polygon 2, 3, …, n on the right. Then you step to polygon 2 on the left. Since polygon 2 has already been compared to polygon 1, you can skip it and start with polygon 3. By the time you get to polygon n, it has already been compared to all other polygons and doesn’t have to be checked at all.
You now have some of the polygons of interest in the left table, and some in the right table, so Rémi selects gid and geom from both, then UNIONs them (a process which automatically strips duplicate rows) in the main body of the query. Unfortunately, if you want more fields, you would have to add them all to the CTE with aliases, and de-alias them in the main body of the query. I wanted something generalizable to any table with any number of columns, so I use a subquery to return only the gids of interest, then drop that into the WHERE criteria [code repeated from above]:
SELECT * FROM table WHERE gid IN (
SELECT DISTINCT unnest(array[a.gid, b.gid]) AS gid
FROM table a JOIN table b
ON (ST_Intersects(a.geom, b.geom) AND a.gid < b.gid)
)
This mashes the gid from the left and right tables into an array, then unnests the array to generate a single column of gids, then uses DISTINCT to eliminate duplicates. The final query returns all columns associated with those gids, without have to explicitly name them. This version of the query ran in approximately 13 minutes on the 2 million record table.
The result:
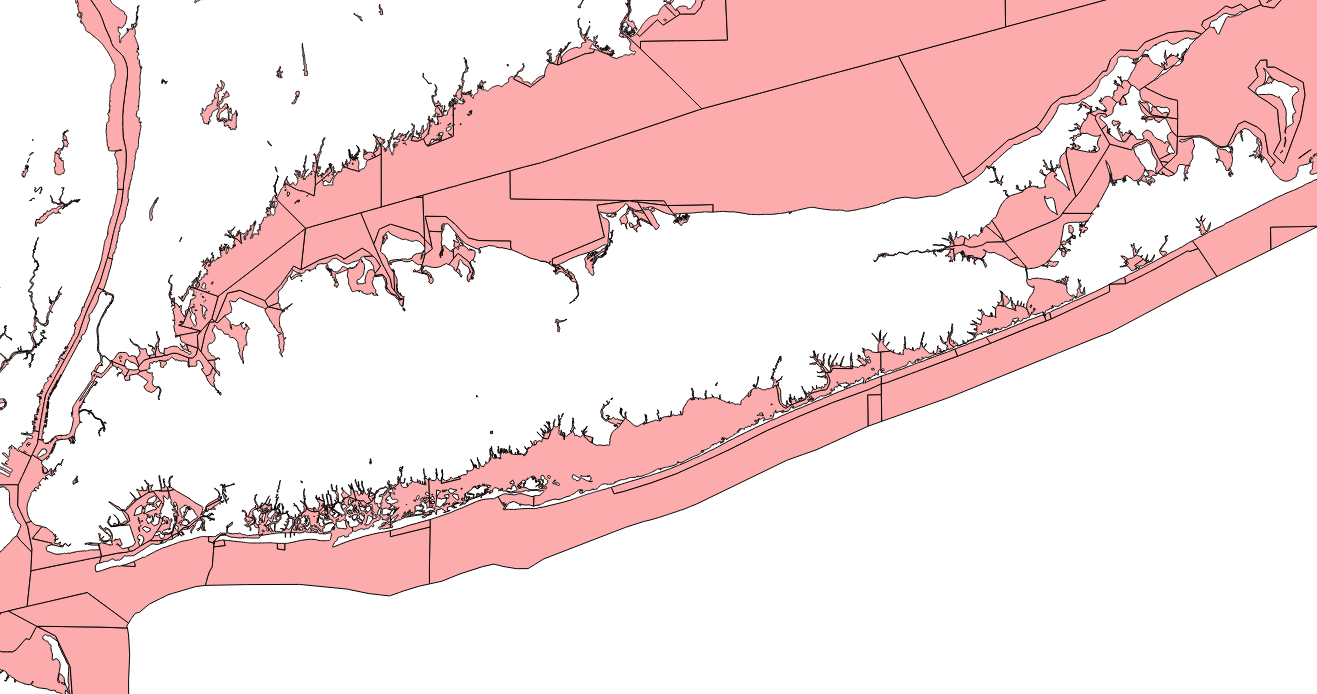
There was one other suggestion to speed up the code (from Brent Wood), which was to use an aspatial attribute to prejoin rows which could potentially be in contact. I used US states as a region identifier to filter polygons in the same state before applying the spatial join. This resulted in quite minor time savings (approximately 30 seconds in the final query) while dropping some polygons that do in fact have neighbors, because they are divided from their neighbors precisely at the state boundary (an artifact of the way the Census distributes the data I was using).